[PAPER REVIEW 230904] GPT2(2018)
author : Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever
1. Abstract
Natural language processing tasks are typically approached with supervised learning on task-specific datasets.
Language models begin to learn these tasks without any supervision.
The capacity of the language model is essential to the success of zero-shot task transfer
*zero-shot task transfer : ability of a model to perform tasks it hasn’t been trained on.
GPT-2 achieves state of the art results on 7 out of 8 datasets.
But still underfits WebText. (inconsistent)
So, the model contain coherent paragraphs of text.
2. Introduction
In current ML systems, there is a lack of generalization.
The prevalence of single task training on single domain datasets is a major contributor to this problem.
We would like to move towards more general systems which can perform many tasks.
Multitask learning is a promising framework for improving general performance.
However, it is still nascent in NLP.
It needs many training pairs(dataset, objective). → very difficult
*multitask learning : each task shares the optimal parameters.
*meta learning : optimizes quickly by targeting fewer datasets than transfer learning.
Language models can perform down-stream tasks in a zero-shot setting.
(without any parameter or architecture modification.)
3. Approach
3.1. Training Dataset
created a new web scrape which emphasized document quality. (unlike Common Crawl)
The resulting dataset is called ‘WebText’.
3.2. Input Representation
prevent BPE from merging across character categories for any byte sequence.
(ex. dog / dog. / dog? / dog!)
This input representation allows us to combine the empirical benefits of word-level LMs with the generality of byte-level approaches.
3.3. Model
use a Transformer based architecture for our LMs.
the model largely follows the details of the OpenAI GPT model.
There is a few modifications.
1) Layer normalization was moved to the input of each sub-block.
2) additional layer normalization was added after the final self-attention block.
3) scale the weights of residual layers at initialization by a factor of 1 / √N
*N = number of residual layers
1) the vocabulary is expanded to 50,257.
2) increase the context size from 512 to 1024 tokens
3) increase a batch size to 512.
4. Experiments
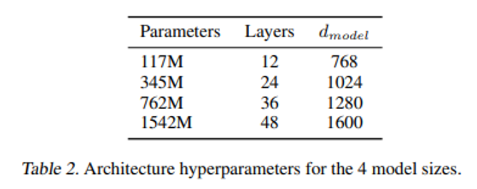
trained and benchmarked 4 LMs.
the smallest model = original GPT
the second smallest model = the largest model of BERT
the largest model is GPT-2.
4.1. Language Modeling
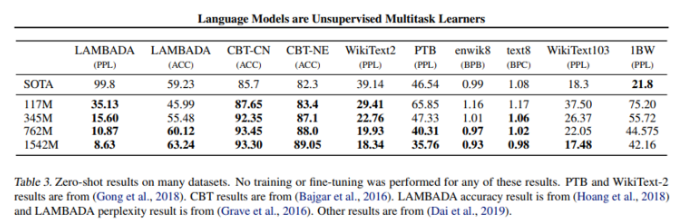
WebText LMs transfer well across domains and datasets.
GPT-2 achieved SOTA in the zero-shot tests of various tasks.
5. Generalization vs Memorization
recent work in computer vision has shown that common image datasets contain a non-trivial amount of near-duplicate images.
this results in an over-reporting of the generalization performance of ML systems.
Similar problems could arise in our WebText.
Therefore it is important to analyze how much test data also shows up in the training data.
→ create Bloom filters (n-gram overlap)
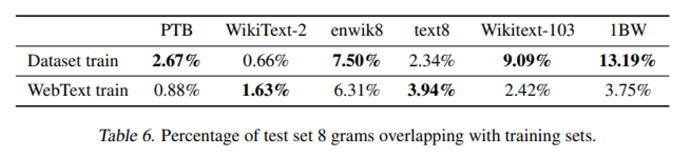
Common LM datasets’ test sets have between 1-6% overlap with WebText train, with an average of overlap of 3.2%.
data overlap between WebText training data and specific evaluation datasets provides a small but consistent benefiit to reported results.
However, for most datasets we do not notice larger overlaps than those already existing between standard training and test sets.
recommend the use of n-gram overlap based de-duplication as an important verification step and sanity check during the creation of training and test splits for new NLP datasets.
GPT-2 is still underfitting on WebText.
6. Discussion
suggest that unsupervised task learning is an additional promising area of research to explore
in terms of practical applications, the zero-shot performance of GPT-2 is still far from use-able.