[Conversational AI 3강] Language Models
서울대 조요한 교수님 Conversational AI 3강 정리
Language Model
- 뒤에 따라올 candidate text의 conditional probability 계산하는 것
- 최신의 dialogue system은 '대부분' LMs로 이루어져 있다.
[질문]
그렇다면 LM 말고 다른 방법론으로 개발된 dialogue system도 있나요?
규칙 기반 챗봇 말고
1. Word2vec
단어를 dense vector로 표현
* dense vector vs sparse vector(one-hot)
* dense vector를 LM의 input으로 사용하기 시작한지 얼마 되지 않았다.
Word Embedding으로 얻어야 하는 특징
- 유사한 단어끼리는 좌표상에서 가까워야 함 = 유사한 벡터
- 유사함의 기준 = 단어가 사용되는 맥락(비슷한 주변 단어)
-> 따라서 word를 input으로 context(주변 단어)를 예측하도록 학습시켜 word embedding을 얻자!
[2가지 학습 알고리즘]
1) Skip-gram
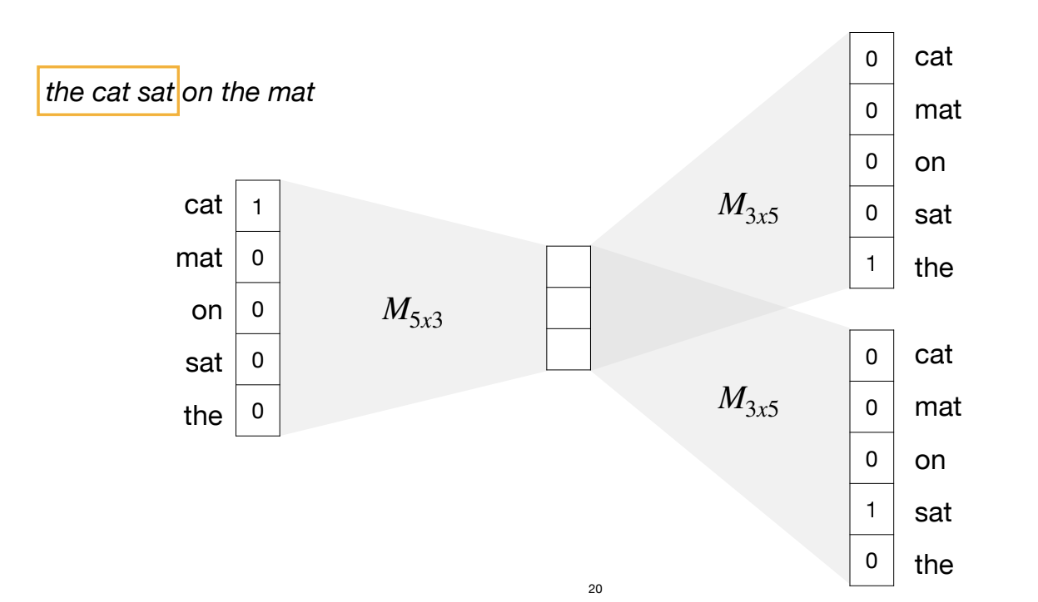
(1) cat의 one hot vector를 input으로
(2) trainable Matrix로 matrix transformation 거쳐서 dense vector로 변환
(3) 이 dense vector로 the의 one hot vector와 sat의 one hot vector를 예측해야 함
-> dense vector에 새로운 trainable matrix로 transformation + softmax 거쳐서 the의 확률이 가장 높게 나오도록 학습
-> dense vector에 새로운 trainable matrix로 transformation + softmax 거쳐서 sat의 확률이 가장 높게 나오도록 학습
(4) sliding window(노란색)을 계속 오른쪽으로 옮기면서 sliding window 별로 학습 시키기
*** input이 원핫이기에 dense vector는 trainable matrix의 특정 row를 가리킴.
-> 예를 들어 cat의 dense vector는 왼쪽 trainable matrix의 첫번째 row
2) CBOW
얘는 반대로 주변 word를 input으로 가운데 단어 예측
[질문]
그럼 CBOW에서 cat의 dense vector는 오른쪽 trainable matrix의 첫 번째 열인가요?

3) 이렇게 학습을 하면
각 vector의 dimension이 interpretable한 특징을 표현 (e.g., 어떤 dimension은 gender, 어떤 dimension은 품사)
4) 단점

??? ㄷㄷ.. 한국어 이정도인 줄은 몰랐네...
얘네 다 학습시키려면...
5) 이를 보완하기 위해 FastText
단어 하나를 Unit으로 보지 말고
단어 안에 character들을 unit으로 보자.
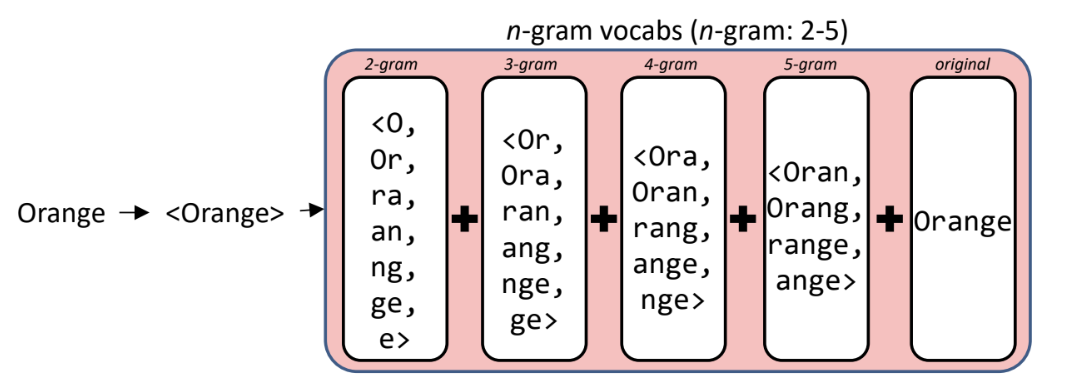
-> 각 ngram들의 word embedding을 합쳐서 orange의 최종 embedding을 만듦
왜 좋아?
- OOV word도 word embedding 생성 가능 -> typo에 robust (word2vec은 불가)
6) Limitations of Word2vect & FastText
- one word can have different meanings -> fixed vector is not flexible
따라서 이러한 한계를 극복하기 위해
BERT, ELMo 탄생!!
2. Seq2Seq model
= encoder-decoder model
- encoder: a sequence of tokens을 embedding
- decoder: embedding을 기반으로 새로운 a sequence of tokens를 생성
얘의 문제점
-> loop (똑같은 말 반복)
-> long sentences에서 성능 안 좋음 (초반 단어 기억 잘 못해)
-> unknown words
3. Attention mechanism
각 input 단어들의 중요도 계산하고 (곱해서 유사도 측정)
그걸로 hidden state들 weighted sum = c
c + (현재 hidden state) 합쳐서 얘로 다음 output token(y) 예측!
-> 모든 encoding 가지고 있을 필요 없이 필요한 input 단어의 encoding만 간직함으로써 메모리 절약
그럼 당연히 현재 자기가 예측하려는 단어 위치에 해당하는 input 단어가 제일 score 높은 거 아니야? 라고 생각할 수 있지만

아님.