[Conversational AI 4강] Language Models 2
서울대 조요한 교수님 Conversational AI 4강 정리
Contextualized Word Embedding
- 하나의 단어가 여러 뜻을 가질 수 있음.
-> 따라서 하나의 vector로 고정하는 게 아니라 context에 의해서 embedding이 바뀌도록
1. Transformer
1) self-attention
query * key = score
softmax(score) * value해서 전부 합하기 (가중합)
self-attention can be computed in parallel
-> query, key, value 단어 별로 따로따로 계산
-> 앞에 있는 거 다 계산될 때까지 기다릴 필요 없다. = 속도 빠름
long-term dependency
2) positional encoding (PE)
1) learned position embedding
2) sine/cosine-base dencoding
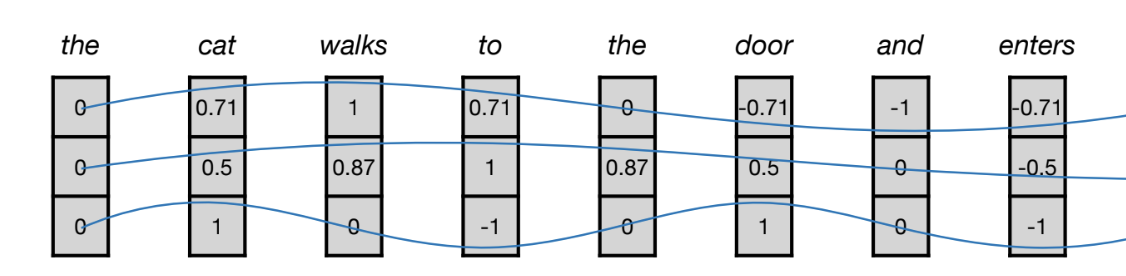
[질문]
주로 어떤 positional embedding 기법이 가장 많이 사용되는지
3) Residual Connections
-> loss function이 매끄러워짐 -> global minima 찾기 쉬움
보통 아래쪽은 (초기 블록) syntax 학습, 윗쪽으로 갈수록 (후기 블록) semantics 학습
2. BERT
트랜스포머의 encoder만 가져와서 pre-train 시킴 (pre-train 유행시킨 아이)
1) MLM (Masked Language Modeling)
-> 각 attention head가 다른 specialty를 가짐
e.g., 누구는 gender 맡고 누구는 syntax 맡고
-> word2vec의 skipgram, cbow와 비슷
2) next sentence prediction
문장 간의 관계 학습 시키기 위해
** [cls] 토큰 사용
-> 근데 얘는 후속 연구에서 훈련에 크게 도움 안된다고 밝혀져서 로버타에서는 아예 빠짐
[교수님께 질문드리기 전에 내가 궁금해서 찾아볼 것들]
perflexity 알고리즘이랑 chatgpt 차이점
perflexity는 transformer 기반이 아닌가? generate 속도가 왜그리 빠르지?
3) downstream tasks
** 전부 [CLS](맨 앞), [SEP](문장 사이 구분) 사용
(1) natural language inference
a. context text (=premise=사실이라고 가정)가 주어짐
b. hypothesis가 true('entail'), false('contradict'), neutral('neutral')인지 분류
(2) single sentence classification tasks
e.g., sentiment classification
(3) question answering tasks
question과 paragraph가 주어지면
paragraph의 몇번째 단어부터 몇번째 단어까지가 정답에 해당하는지 찾는 과제
start embedding, end embedding이 따로 존재해서 걔네랑 dot product 한 후 가장 값 높은 애를 starting/ending word로 간주함.
(4) single sentence tagging tasks
- named entity recognition: identiy 객체
e.g., "I": person, "home": location, "Seoul": location
-> 객체가 아닌 애들은 O로 표현 (O: Other)
e.g., was, a, puppet
-> ##son, ##eer -> X로 표현 (앞이랑 연결되는 토큰)
4) Tokenization in BERT
wordpiece tokenization
-> 우선 ##u, ##a, ##m ... 이런 형태로 죄다 쪼개고
-> 전체 vocabulary 중 붙어서 나타나는 횟수가 가장 높은 토큰 조합 찾고 합쳐
-> 원하는 size의 vocab가 될 때까지 반복
**question answering task에 대해 finetuning 해놓은 모델이 다른 tasks에도 좋은 성능을 보임.