
link : https://arxiv.org/pdf/1907.11692.pdf
by University of Washington, Seattle, Wa & Facebook AI
1. Introduction
Language model pretraining has led to significant performance gains.
but,
- training is computaionally expensive
- training often done on private datasets of different sizes
- hyperparameter choices have significant impact on the final results.
→ so, we present a replication study of BERT pretraining.
- carefully evaluate the effects of hyperparameter tuning and training set size.
- we find that BERT was significantly undertrained
- we propose an improved recipe for training BERT models, RoBERTa
*replication study(재현 연구) : a study that validates the results of a previously published study
*simple modifications
- train the model longer, with bigger batches, over more data
- remove the next sentence prediction objective
- train on longer sequences
- apply dynamically changing masking pattern to the training data
- collect a large new dataset (CC-NEWS)
*the contributions of this paper
- present a set of important BERT design choices and training strategies
- confirm that using more data for pretraining further improves performance on down-stream tasks.
- our training improvements show that masked language model training objective is competitive with other recently published methods.
2. Experimental Setup
2.1 Implementation
we reimplement BERT in FAIRSEQ
*FAIRSEQ(Facebook AI Research Sequence-to-Sequence Toolkit) : is a sequence modeling toolkit that allows researchers and developers to train custom models for translation, summarization, language modeling and other text generation tasks.
we primarily follow the original BERT optimization hyperparameters,
except for the peak learning rate and number of warmup steps.
*lr warmup : slowly raising the learning rate
<parameters of Adam optimizer>
- training to be very sensitive to the Adam epsilon term
- in some cases, tuning the Adam epsilon term results in better performance.
- setting B2 = 0.98 to improve stability when training with large batch sizes.
pretrain sequences of at most 512 tokens unlike before
- do not randomly inject short sequences
- do not train with a reduced sequence length
- train only with full-length sequences.
2.2 Data
increasing data size can result in improved performance.
five English-language corpora of varying sizes and domain
- Book Corpus (original data used to train BERT)
- English Wikipedia (original data used to train BERT)
- CommonCrawl News dataset
- OpenWebText
- STORIES
2.3 Evaluation
evaluate our models using the following 3 benchmarks.
1) GLUE (General Langage Understanding Evaluation)
- a Benchmark for evaluating natural language understanding.
- consists of 9 task datasets that are diverse and difficult to resolve.
2) SQuAD(Stanford Question Answering Dataset)
- evaluates machine reading comprehension
- a large dataset of 100,000 questions and answers
3) RACE (ReAding Comprehension from Examinations)
- a large-scale reading comprehension dataset
- has siginificantly longer context than other popular reading comprehension datasets
3. Training Procedure Analysis
3.1. Static vs Dynamic Masking
1) Static mask
original BERT performed masking once during data preprocessing
to avoid using the same mask for each training instance
→ training data was duplicated 10 times
→ each training instance is masked in 10 different ways
→ 40 epoches of training
2) Dynamic Masking
generate the masking pattern every time we feed a sequence to the model.
is better than static masking

3.2. Model Input Format and Next Sentence Prediction
in training the original BERT, NSP loss was hypothesized to be an important factor.
compare several alternative training formats.
1) segment-pair + NSP : originial input format used in BERT
2) sentence-pair + NSP
3) full-sentences + without NSP : sampled contiguously from one or more documents
4) doc-sentences + without NSP : may not cross document boundaries
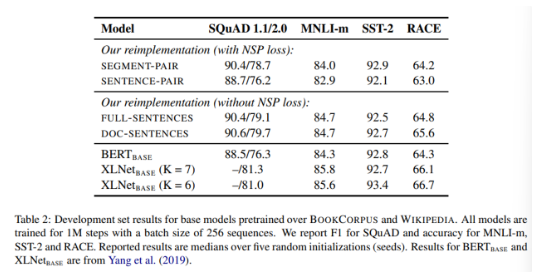
<result>
1) using individual sentences hurts performance on downstream tasks
→ hypothesize is because the model is not able to learn long-range dependencies.
2) removing the NSP loss matches or slightly improves downstream task performance.
3) doc-sentences model performs slightly better than full-sentences model.
- however, we use full-sentences because the doc-sentences format reuslts in variable batch sizes.
3.3 Training with large batches

3.4 Text Encoding
Byte-Pair Encoding(BPE)
- a hybrid between character- and word-level representations
- relies on subwords units
- using bytes makes it possible to learn a subword vocabulary of a modest size
- encode any input text without introducing “un-known” tokens.
original BERT uses a character-level BPE of size 30k, which is learned after preprocessing the input with heuristic tokenization rules.
instead we consider training BERT with a larger byte-level BPE containing 50k subword units, without any additional preprocessing.
4. RoBERTa
now aggregate these modifications and evaluate their combined impact.
we call this configuration RoBERTa (Robustly optimized BERT approach)
RoBERTa is trained with
1) dynamic masking
2) Full-Sentences without NSP loss
3) large mini-batches
4) larger byte-level BPE
additionally, we investigate 2 other factors that have been under-emphasized in previous work.
1) the data used for pretraining
2) the number of training passes through the data
train RoBERTa
1) begin by training RoBERTa following the BERT-large architecture (Layers=24, Hidden dimension=1024, Multi-Head Attention=16, 355M parameters(w, b))
2) pretrain for 100K steps using 1024 V100 GPUs for approximately 1 day.

The longer the pre-training, the higher the performance.
even longest-trained model does not appear to overfit our data
evaluate our best RoBERTa model on the 3 different benchmarks
1. GLUE results
the median development set results for each task over 5 random initializations, without model ensembling.
our submission depends only on single-task finetuning.

RoBERTa achieves SOTA.
but, RoBERTa uses the same MLM objective and architecture as BERT-large, yet consistently outperforms both BERT-large and XLNet-large.
This raises questions about the relative importance of model architecture and pre-training objective, compared to more mundane details like dataset size and training time.
2. SQuAD results

3. RACE Results

5. Conclusion
performance can be substantially improved by training the model longer, with bigger batches over more data.
these previously overlooked design decisions are important
and BERT’s pretraining objective remains competitive with recently proposed alternatives.