
서울대 조요한 교수님 Conversational AI 9강 정리
1. DialoGPT
2020년 개발
GPT-2를 conversational data에 학습
no fine-tuning
1) pre-training
데이터셋 = reddit 데이터 속 (post + comment + comment의 comment)를 하나의 dialogue로 간주

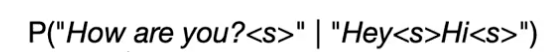
2) Inference
(1) Greedy Decoding = 가장 확률 높은 애 내뱉는
-> 문제점: 앞쪽 단어 등장 확률이 낮으면 전체적으로 좋은 response임에도 불구하고 output으로 나올 수 없음
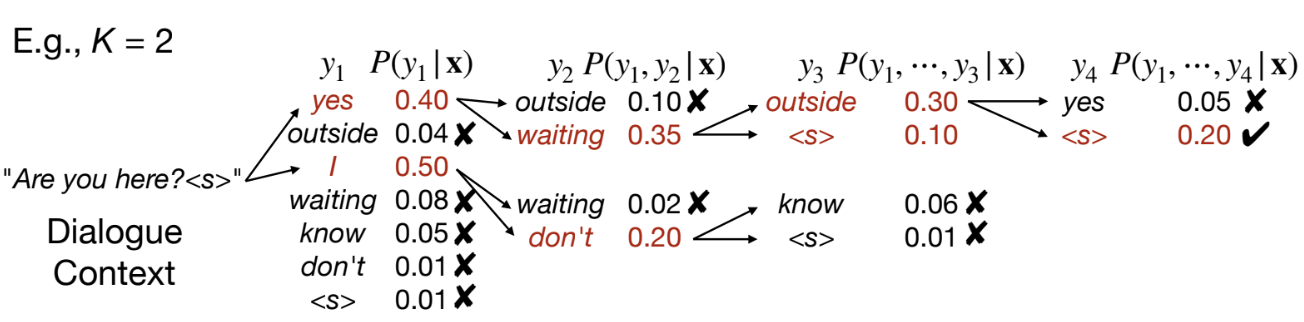
(2) Beam Search = after each decoding step, keep at most K (partial) responses with the highest probability
3) Promoting response diversity
(1) maximum mutual information (MMI)
= reverse language modeling
= response가 주어졌을 때 앞에 해당 context가 나올 확률

[질문]
P("I love movies" | "OK")를 구하게 되면
분자가 P("I love movies <s> OK") 와 같은 형태가 되나요?
그냥 위 사진과 같은 공식이면
I love movies가 OK 앞에 나올 확률 뒤에 나올 확률 전부 합하는 꼴이 되지 않나요?
4) evaluation
(1) DSTC-7 test

[질문]
1. pretraining dataset도 똑같이 reddit이 source인데 evaluation이 제대로 되었다 평가될 수 있는지
2. 사람들은 의도적으로 다른 사람과 비슷하지 않은 답변을 달려고 할테니까 모델의 response와 더욱 정확한 비교를 하려면 기존에 있던 comment 데이터 중 하나를 human response로 간주하는 게 아니라 기존의 ground truth를 보지 않고 모델이 답변 생성한 것처럼 실제 사람도 새로운 답변을 작성하여 새로운 실험 데이터를 만들어야하지 않았을까 궁금합니다.
(2) reddit multi-reference dataset
1) relevance
2) informative
3) human-like
성능은
DialoGPT + MMI > Human > DialoGPT > DialoGPT + Beam 순으로 좋았다.
2. LaMDA
limitations of purely LM-based systems -> Nonsensical, Rude, Incorrect
을 극복하기 위해
구글이
Language Model for Dialogue Applications 개발!
1) 3 main goals: quality, safety, groundedness
(1) quality
a. sensible: 자기 모순 안됨
b. specific: general한 response 안됨
c. interesting
(2) Groundedness: 출처 명확해야
2) self evaluation during inference
(1) beam search로 candidate responses 만들고
(2) 각 candidate response들을 위 quality 기준으로 평가 -> 가장 점수 높은 response를 최종으로 선택 (평가 finetuning)

[질문]
왜 sensible score에만 곱하기 3 하나요?
중요도? 어떤 기준을 근거로?
질문 유형에 따라 sensible 보다 interesting이 더 중요할 수도 있지 않나?
3) generative(pre-training) + discriminative (fine-tuning)
4) grounding in tools during inference
while generating a response, LaMDA use external tools
toolset(TS): consists of a calculator, a translator, and an information retrieval system
grounding 과정도 finetuning 시켜야 함
서울대 조요한 교수님 Conversational AI 9강 정리
1. DialoGPT
2020년 개발
GPT-2를 conversational data에 학습
no fine-tuning
1) pre-training
데이터셋 = reddit 데이터 속 (post + comment + comment의 comment)를 하나의 dialogue로 간주
2) Inference
(1) Greedy Decoding = 가장 확률 높은 애 내뱉는
-> 문제점: 앞쪽 단어 등장 확률이 낮으면 전체적으로 좋은 response임에도 불구하고 output으로 나올 수 없음
(2) Beam Search = after each decoding step, keep at most K (partial) responses with the highest probability
3) Promoting response diversity
(1) maximum mutual information (MMI)
= reverse language modeling
= response가 주어졌을 때 앞에 해당 context가 나올 확률
[질문]
P("I love movies" | "OK")를 구하게 되면
분자가 P("I love movies <s> OK") 와 같은 형태가 되나요?
그냥 위 사진과 같은 공식이면
I love movies가 OK 앞에 나올 확률 뒤에 나올 확률 전부 합하는 꼴이 되지 않나요?
4) evaluation
(1) DSTC-7 test
[질문]
1. pretraining dataset도 똑같이 reddit이 source인데 evaluation이 제대로 되었다 평가될 수 있는지
2. 사람들은 의도적으로 다른 사람과 비슷하지 않은 답변을 달려고 할테니까 모델의 response와 더욱 정확한 비교를 하려면 기존에 있던 comment 데이터 중 하나를 human response로 간주하는 게 아니라 기존의 ground truth를 보지 않고 모델이 답변 생성한 것처럼 실제 사람도 새로운 답변을 작성하여 새로운 실험 데이터를 만들어야하지 않았을까 궁금합니다.
(2) reddit multi-reference dataset
1) relevance
2) informative
3) human-like
성능은
DialoGPT + MMI > Human > DialoGPT > DialoGPT + Beam 순으로 좋았다.
2. LaMDA
limitations of purely LM-based systems -> Nonsensical, Rude, Incorrect
을 극복하기 위해
구글이
Language Model for Dialogue Applications 개발!
1) 3 main goals: quality, safety, groundedness
(1) quality
a. sensible: 자기 모순 안됨
b. specific: general한 response 안됨
c. interesting
(2) Groundedness: 출처 명확해야
2) self evaluation during inference
(1) beam search로 candidate responses 만들고
(2) 각 candidate response들을 위 quality 기준으로 평가 -> 가장 점수 높은 response를 최종으로 선택 (평가 finetuning)
[질문]
왜 sensible score에만 곱하기 3 하나요?
중요도? 어떤 기준을 근거로?
질문 유형에 따라 sensible 보다 interesting이 더 중요할 수도 있지 않나?
3) generative(pre-training) + discriminative (fine-tuning)
4) grounding in tools during inference
while generating a response, LaMDA use external tools
toolset(TS): consists of a calculator, a translator, and an information retrieval system
grounding 과정도 finetuning 시켜야 함