
링크 : https://arxiv.org/pdf/1909.11942.pdf
학회지 : ICLR 2020
발표 연도 : 2019
*self-supervised learning :
- 2단계로 구성.
1) Pre-trained 모델 생성 : untagged data 이용해서 전반적인 특징 학습하고
2) Downstream task : 소량의 tagged data 이용해서 Pre-trained model fine tuning

0. Abstract
ALBERT is A Lite version of BERT (have fewer parameters compared to BERT-large)
1) Characteristics
(1) use 2 parameter reduction techiniques
- to address the following problems
- → BERT’s model size is too big → memory limitation, long training time
(2) use self-supervised loss
- focuses on modeling inter-sentence coherence
- helps downstream tasks with multi-sentence inputs
1. Introduction
The larger the model, the higher the performance.
1) Problem :
(1) memory limitation - hardware
(2) long training time - the communication overhead of distributed training
*Distributed training :
1. 작업 분할 방식
1) Model Parallelism - 모델을 여러 GPU에 분산 처리
2) Data Parallelism - 데이터를 여러 GPU에 분산 처리
2. Parameter 동기화 방식
1) Synchronous replication
- 분산 처리가 모두 끝났을 때, Gradient 평균으로 Parameter 업데이트
2) Asynchronous replication
- 각 분산 처리에서 Gradient 계산이 끝난 건, 먼저 Parameter 업데이트
3. Gradient 취합 방식
1) All-Reduce (Parameter Server) -Parameter Server가 취합한 Gradient(평균) 재분배

2) Ring-AllReduce - 모든 GPU를 Ring 형태로 구성 후, Gradient 전달을 통해 공유


출처 : https://wooono.tistory.com/331
[DL] Distributed Training (분산 학습) 이란?
Distributed Training (분산 학습) 이란? 딥러닝 모델 설계 과정에는 많은 시간이 소요됩니다. 따라서, 모델의 학습 과정을 가속화하는 것은 매우 중요합니다. 분산 학습은 이러한 딥러닝 모델의 학습
wooono.tistory.com
2) Existing Solutions :
(1) model parallelization
(2) clever memory management
→ address the memory limitation problem, but not the communication overhead.
3) Our Solutions :
(1) 2 parameter reduction techniques
a. factorized embedding parameterization
- decompose the large vocabulary embedding matrix into 2 small matrices.
- seperate the size of the hidden layers from the size of vocabulary embedding.
→ makes it easier to grow the hidden size without increasing the parameter size of vocabulary embeddings.
b. cross-layer parameter sharing
(2) effect
a. An ALBERT configuration similar to BERT-large has
- 18x fewer parameters
- 1.7x faster training
- act as regularization
- helps with generalization.
4) Additional modification :
(1) use SOP(sentence-order prediction)
- self-supervised loss
- focues on inter-sentence coherence
- address the ineffectiveness of NSP loss
5) Result : achieve new SOTA on GLUE, SQuAD, and RACE
*Gradient Checkpointing :
- 연산 시간 증가, 메모리 사용량 하락.
- 순전파 과정에서 모든 노드의 가중치를 저장하던 것을 일부만 저장.
2. The Elements of ALBERT
2-1. Model Architecture Choices
- backbone : transformer encoder with GELU (similar to BERT)
*GELU(Gaussian Error Linear Unit) : 최신 딥러닝 모델에서 사용되는 activation function

1) Factorized embedding parameterization
- BERT : E(embedding size) = H(hidden layer size)
a. project the one-hot vectors directly into the hidden space of size H.
- ALBERT : E < H
a. project the one-hot vectors into a lower dimensional embedding space of size E,
b. and then project it to the hidden space.
→ decompose embedding parameters into 2 smaller matrices
→ ((V x H) to (V x E + E x H)
2) Cross-layer parameter sharing
- share all parameters across layers.
- our embeddings are oscillating rather than converging.
- transition from layer to layer are much smoother → stabilize network parameters.

3) Inter-sentence coherence loss
(1) NSP(topic prediction + coherence prediction) was eliminated
- topic prediction is easier to learn compared to coherence prediction
- topic prediction overlaps more with what is learned using the MLM loss
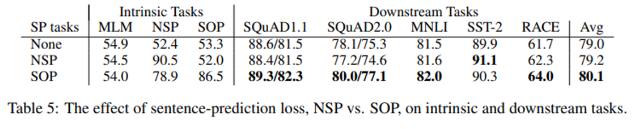
(2) Instead, use SOP(sentence-order prediction)
- avoids topic prediction and focuses on modeling inter-sentence coherence
- positive examples : 2 consecutive segments from the same document (the same with BERT)
- negative examples : swap order of postiive examples
(3) SOP is better than NSP
2-2. Model Setup

3. Experimental Results
3-1. Experimental Setup : follow the BERT
3-2. Overall comparison between BERT and ALBERT
1) ALBERT achieves significant improvements
2) higher data throughput

3-3. Ablation experiments
1) Factorized embedding parameterization
(1) non-shared condition (BERT-style) : larger embedding sizes give better performance, but not by much
(2) all-shared condition (ALBERT-style) : embedding size 128 is the best

2) Cross-Layer parameter sharing
(1) divide the L layers into N groups of size M
(2) each size-M group shares parameters
→ the smaller the group group size M is, the better the performance we get.
→ however decreasing group size M also increase the number of parameters.
- choose all-shared strategy as default.

3) Sentence order prediction (SOP)
3-4. What if we train for the same amount of time?
1) train for roughly the same amount of time
2) ALBERT-xxlarge is better than BERT-large (+1.5% Avg, +5.2% RACE)

3-5. Additional training data and dropout effects

1) additional training data

2) dropout effects
- even after training for 1M steps, ALBERT-xxlarge still do not overfit
→ so, remove dropout
- authors are the first to show that dropout can hurt performance in large Transformer-base models.
→ however, ALBERT is a special case of the transformer
→ so, further experimentation is needed

3-6. SOTA

+17.4% over BERT (RACE)